运维的最佳实践:搜狐畅游自动化运维之旅!
搜狐黎志刚见证了畅游游戏自动化运维平台的从无到有,通过在其中踩过的坑、解过的结,他向大家来阐述游戏运维的进阶之路。本文主要围绕畅游游戏管理体系与运维自动化的演变历程、运维自动化的实现及未来运维四方面展开。

畅游运维管理体系与运维自动化的演变历程 畅游运维管理体系演变历程
从 2008 年毕业以实习生的身份进入搜狐畅游,我同公司一起成长,经历了整个运维管理体系从小到大的过程。
整个运维管理体系是从最初石器时代(脚本化),之后的青铜时代(半自动化)、蒸汽时代(DevOPS)一路演变过来,现在处于自动化和智能化过渡阶段。
畅游运维自动化演变历程
如下图,是畅游运维自动化的步骤,分别是数据总线统一、业务自动化、标准化统一、服务驱动和智能运维。

对于已发生故障进行分析发现,40% 的故障由数据不准确导致。出现这样情况,是因为自产信息或很多系统之间交互信息带来的问题。
所以首要做的是数据的系统、准确性、调用及引用接口的统一。之后对数据和文件分发研发了一系列平台,还有各个平台标准化的统一。
如下图,是畅游运维体系架构:
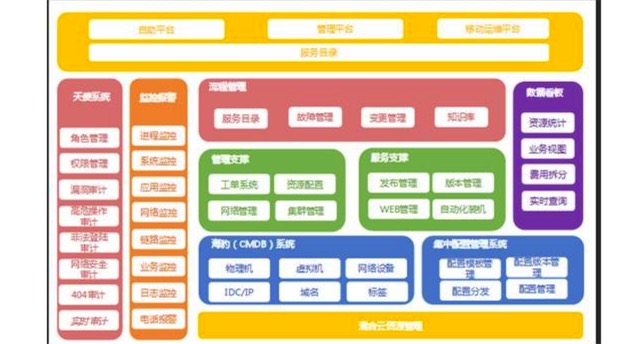
最底层采用的是混合云的模式,在这基础上,又建设了多个如海豹、集中配置管理、管理和服务相关的支撑系统,还有最重要的天使和监控告警系统。
天使系统的主要职责就是权限管理,畅游各运维人员所负责的游戏各有不同,由于游戏版本的特殊性,一旦泄露,会对整个游戏的营收造成很大影响。
所以,要严格管理每个工程师的权限。监控警报系统之所以重要,是因为涉及到所有游戏玩家的体验和收入。
畅游游戏运维自动化实现 游戏运维的特点和痛点
面对这样的运维体系架构,畅游都在哪些部分做了自动化呢?我们先来看看游戏运维有哪些特点和痛点。
每个游戏的构架和应用场景,乃至于所使用的数据库和开发语言完全不同。还有不同国籍开发的游戏,整个操作系统和数据库环境、版本都存在大量的不同点。这样一来,运维整个平台和环境都要面临很大挑战。
游戏运维的痛点有很多,如:
运维脚本及工具零散、数量多、难复用。
资源需求弹性大。
成本、效率与可用性的平衡。
大流量的高并发。
故障需要实时处理且尽快恢复。
多版本管理。
为克服这些痛点,近四五年,畅游运维做了很多事情,业务和工程师人数等方面都有变化。
从 2014 年到 2016 年,业务每年实现 20% 的增长,全职工程师在不断的减少,这是因为 2014 年到现在,我们做了大量的自动化工具,利用自动化平台和资源整合,每年资源成本减少 30%。
2016 年 CMDB 海豹系统上线,对所有在线资源进行整合,公共集群建设的完成,把单游戏和每一组游戏所需公共服务放在一起,使得资源成本减少 50%。
这里值得一提的有趣现象是 2014 年到 2015 年的人为故障数量基本持平,这是自动化带来的副作用,2016 年人为故障下降了 30%,此时自动化的作用开始发挥出来了。
2014 年到 2015 年的全局故障率(网络故障、硬件故障等所有的故障)减少了 20%,2016 年故障率下降了 35%。
我们为什么可以在业务增长的情况下,依然可以做到故障下降和成本节约?
分析原因如下:
40% 的人为故障是由于信息不准确或是人为操作失误导致的。
30% 的人为故障是由于跳流程操作和研发的沟通壁垒。
50% 以上的成本来自于空闲资源和故障资源,以及服务器性能资源未能充分使用。
针对这些原因,畅游运维做了很多事情,下面主要分享如何通过海豹系统做信息的统一化和标准化、PaaS 平台实现 Devops 自动化交付以及 Docker 容器技术和混合云架构等内容。
游戏运维自动化平台的技术及逻辑架构
对于游戏运维自动化平台应用来说,是既定的计划,可以当做任务来执行,所有开服、关服、更新、数据回档及档案恢复等所有操作都可以定义成任务或工作流,之后把所有的设计全部按照任务系统的架构来设计即可。
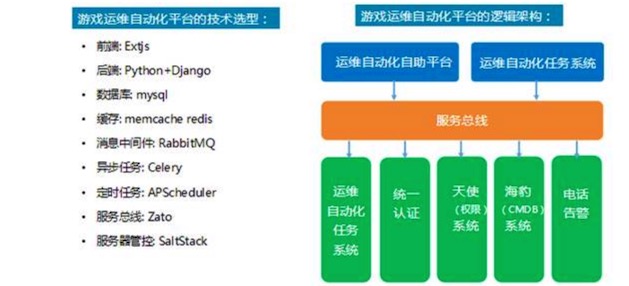
在平台设计过程中,系统主要使用 Python 来进行开发。因为从 2015 年开始,我们发现,如果全部用 Java 来开发的话,运维人员的参与度会非常低。
假设运维人员对 Java 不了解,运维和开发之间需求沟通就不顺畅。这里的解决方案就是一线运维人员必须要懂 Python,而且要参与到开发过程中。
如下图,是自动化运维任务的系统架构:
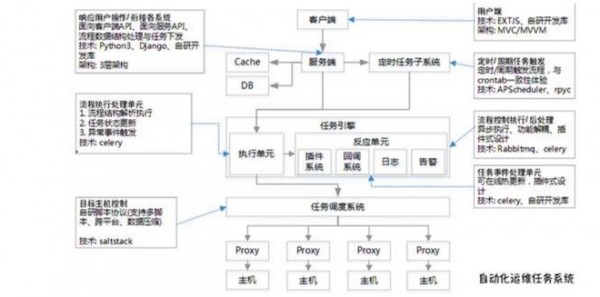
自动化运维任务系统是结合开源技术与公司现有资源的运维的基础操作平台。不仅支持脚本执行、定时任务等基础运维场景外,还提供了流程式开发框架,使运维人员能开发自己需要的业务维护功能。
海豹系统(CMDB)
海豹系统承载畅游硬件层、应用层和网络层等运维层所有信息的记录,如设备、配置、关联权限、关联拓扑、关联环境、关联流程等。基于这些信息,以应用为核心,通过业务场景进行驱动。
如下图,是海豹系统(CMDB)的功能架构:

整个功能架构从下至上分为数据来源、数据层和应用层部分。用以管理系统中心的服务器及相关的软硬件资产信息,是所有系统资产信息的来源。数据层对所有资产进行查询、变更及管理,通过统计报表模块图展示资产的情况。
如下图,是海豹系统(CMDB)的功能架构和技术架构:

这是海报系统的最初时期,由不足五人用 Java 写的核心架构。引擎部分,之所以还在用 JSP 和 Freemarker 引擎,是为了兼顾老的系统。
如下图,是海豹系统(CMDB)的界面:
所有的端游、手游的信息会集中到海报系统,意味着资产管理专员可以通过这个平台做所有资源初始化和分配调度。
PAAS平台
通过业务逻辑把各个资源统筹起来,资源所见即所得,更容易的实现了持续集成,通过各项基础服务的组合,实现代码自动化发布、应用管理、环境初始化部署、线上运维一体化集成,提升项目代码编译、测试、发布效率。
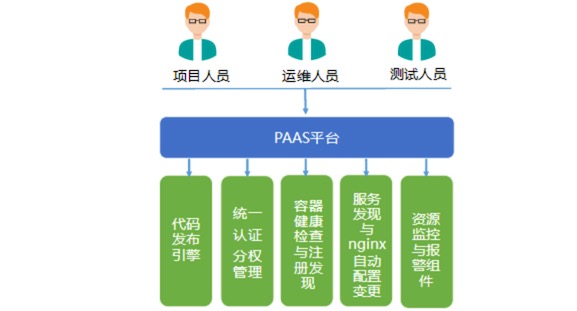
PAAS 平台主要职责如下:
提供一致性环境保障。
提供应用多租户隔离以及资源的多租户隔离。
提供服务发现、可弹性伸缩、状态管理、资源分配、动态调度等能力。
支持预发布、一键发布、一键回滚以及自动化部署。
提供透明化的监控、容灾能力。
提供运维、开发、测试多角度业务场景。
如下图,是 PAAS 平台的主要技术选型:
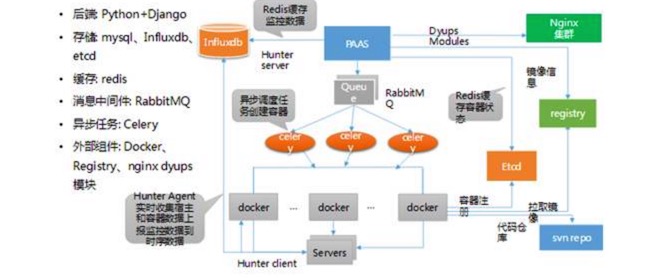
从上图可以看出,PAAS 平台里也包含外部组件,Docker 也包含其中。因为游戏公司大量代码基本都放到 SVN,所以我们也会选在 SVN 来管理。
Docker 容器技术
PAAS 平台的设计中,核心部分是 Docker。那搜狐畅游的 Docker 是如何设计的呢?
如下,是原 Docker 架构图:

如下,是最终版的 Docker 架构图:
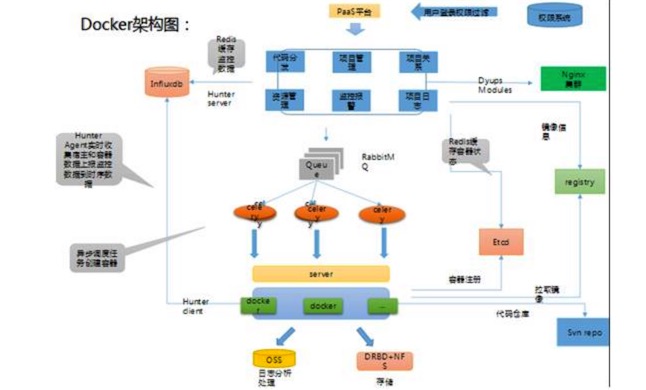
从 2014 年至今,我们已经迭代过两个版本,搜狐畅游在容器监控数据共享、稳定性和镜像管理等方面进行了优化。
如下图,是技术演化对比:
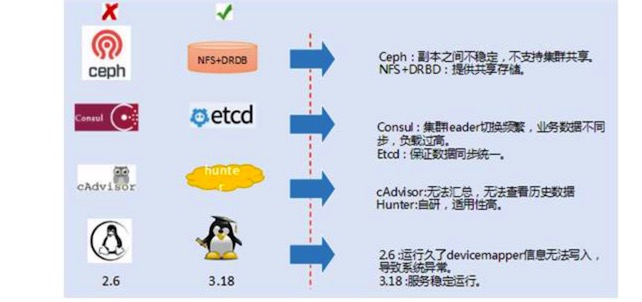
因 Ceph 副本之间不稳定,不支持集群共享,所以改成 NFS+DRBD。因 Consul 集群 Leader 切换频繁,业务数据不同步,负载过高,改成 Etcd,来保证数据同步统一。
为应对 cAdvisor 无法汇总,无法查看历史数据的问题,我们自研了 Hunter。操作系统从 2.6 升级到 3.18,应对运行久了后 devicemapper 的信息无法写入导致系统异常的问题。
混合云结构
畅游运维体系最底层采用的是混合云结构,开始考虑的方式是直接接入所有公有云,用专业的方式打通,但游戏需要 BGP(网关协议)。
这意味着必须多线接入,除电信、联通外,所有的小区宽带,第三方宽带也必须要接入,所以需要选择混合云的结构。

选择混合云相比畅游 IDC 降低成本在 20% 左右,并且使资源弹性,云上云下,扩缩容更快速。在可靠性方面,不仅可实现异地双活,还有抗攻击、DNS 劫持、冗余可靠等优势。
畅游运维管理体系的下一步探索
畅游运维管理体系的下一步将把持续交付的分层能力和公共服务标准化作为探索方向。
持续交付的分层能力

在畅游运维做自动化时,会利用可持续交付的理念和原则去做。工具开发过程中,一定要注意的问题是:工具越多,工具与工具之间的调用就会出现大量的问题。
所以一定要进行平台化和做成集群式服务,否则成本不会降低,反而故障依旧会很多。
公共服务标准化
如下图,是公共服务平台整合架构:

畅游把 redis、Nginx、MySQL 等集群全部接入,不需要做其他的事情。
写在最后
畅游运维做整个自动化过程中的心得有三个:
简单有效,不要做特别花哨,因为对应用最实际才是有用的,对应用或开发人员来说,最有效及效率最高是最好的。
符合实际业务,不是脱离研发和应用。
高效,游戏特性决定必须高效,快上快下,快速决策。
以上内容根据黎志刚老师在 DevOps 与持续交付专场的演讲内容整理。
摘自:http://www.sohu.com/a/159781943_655957
运维的最佳实践:搜狐畅游自动化运维之旅!

游客
会员积分:201900
搜狐黎志刚见证了畅游游戏自动化运维平台的从无到有,通过在其中踩过的坑、解过的结,他向大家来阐述游戏运维的进阶之路。本文主要围绕畅游游戏管理体系与运维自动化的演变历程、运维自动化的实现及未来运维四方面展开。
畅游运维管理体系与运维自动化的演变历程 畅游运维管理体系演变历程
从 2008 年毕业以实习生的身份进入搜狐畅游,我同公司一起成长,经历了整个运维管理体系从小到大的过程。
整个运维管理体系是从最初石器时代(脚本化),之后的青铜时代(半自动化)、蒸汽时代(DevOPS)一路演变过来,现在处于自动化和智能化过渡阶段。
畅游运维自动化演变历程
如下图,是畅游运维自动化的步骤,分别是数据总线统一、业务自动化、标准化统一、服务驱动和智能运维。
对于已发生故障进行分析发现,40% 的故障由数据不准确导致。出现这样情况,是因为自产信息或很多系统之间交互信息带来的问题。
所以首要做的是数据的系统、准确性、调用及引用接口的统一。之后对数据和文件分发研发了一系列平台,还有各个平台标准化的统一。
如下图,是畅游运维体系架构:
最底层采用的是混合云的模式,在这基础上,又建设了多个如海豹、集中配置管理、管理和服务相关的支撑系统,还有最重要的天使和监控告警系统。
天使系统的主要职责就是权限管理,畅游各运维人员所负责的游戏各有不同,由于游戏版本的特殊性,一旦泄露,会对整个游戏的营收造成很大影响。
所以,要严格管理每个工程师的权限。监控警报系统之所以重要,是因为涉及到所有游戏玩家的体验和收入。
畅游游戏运维自动化实现 游戏运维的特点和痛点
面对这样的运维体系架构,畅游都在哪些部分做了自动化呢?我们先来看看游戏运维有哪些特点和痛点。
每个游戏的构架和应用场景,乃至于所使用的数据库和开发语言完全不同。还有不同国籍开发的游戏,整个操作系统和数据库环境、版本都存在大量的不同点。这样一来,运维整个平台和环境都要面临很大挑战。
游戏运维的痛点有很多,如:
运维脚本及工具零散、数量多、难复用。
资源需求弹性大。
成本、效率与可用性的平衡。
大流量的高并发。
故障需要实时处理且尽快恢复。
多版本管理。
为克服这些痛点,近四五年,畅游运维做了很多事情,业务和工程师人数等方面都有变化。
从 2014 年到 2016 年,业务每年实现 20% 的增长,全职工程师在不断的减少,这是因为 2014 年到现在,我们做了大量的自动化工具,利用自动化平台和资源整合,每年资源成本减少 30%。
2016 年 CMDB 海豹系统上线,对所有在线资源进行整合,公共集群建设的完成,把单游戏和每一组游戏所需公共服务放在一起,使得资源成本减少 50%。
这里值得一提的有趣现象是 2014 年到 2015 年的人为故障数量基本持平,这是自动化带来的副作用,2016 年人为故障下降了 30%,此时自动化的作用开始发挥出来了。
2014 年到 2015 年的全局故障率(网络故障、硬件故障等所有的故障)减少了 20%,2016 年故障率下降了 35%。
我们为什么可以在业务增长的情况下,依然可以做到故障下降和成本节约?
分析原因如下:
40% 的人为故障是由于信息不准确或是人为操作失误导致的。
30% 的人为故障是由于跳流程操作和研发的沟通壁垒。
50% 以上的成本来自于空闲资源和故障资源,以及服务器性能资源未能充分使用。
针对这些原因,畅游运维做了很多事情,下面主要分享如何通过海豹系统做信息的统一化和标准化、PaaS 平台实现 Devops 自动化交付以及 Docker 容器技术和混合云架构等内容。
游戏运维自动化平台的技术及逻辑架构
对于游戏运维自动化平台应用来说,是既定的计划,可以当做任务来执行,所有开服、关服、更新、数据回档及档案恢复等所有操作都可以定义成任务或工作流,之后把所有的设计全部按照任务系统的架构来设计即可。
在平台设计过程中,系统主要使用 Python 来进行开发。因为从 2015 年开始,我们发现,如果全部用 Java 来开发的话,运维人员的参与度会非常低。
假设运维人员对 Java 不了解,运维和开发之间需求沟通就不顺畅。这里的解决方案就是一线运维人员必须要懂 Python,而且要参与到开发过程中。
如下图,是自动化运维任务的系统架构:
自动化运维任务系统是结合开源技术与公司现有资源的运维的基础操作平台。不仅支持脚本执行、定时任务等基础运维场景外,还提供了流程式开发框架,使运维人员能开发自己需要的业务维护功能。
海豹系统(CMDB)
海豹系统承载畅游硬件层、应用层和网络层等运维层所有信息的记录,如设备、配置、关联权限、关联拓扑、关联环境、关联流程等。基于这些信息,以应用为核心,通过业务场景进行驱动。
如下图,是海豹系统(CMDB)的功能架构:
整个功能架构从下至上分为数据来源、数据层和应用层部分。用以管理系统中心的服务器及相关的软硬件资产信息,是所有系统资产信息的来源。数据层对所有资产进行查询、变更及管理,通过统计报表模块图展示资产的情况。
如下图,是海豹系统(CMDB)的功能架构和技术架构:
这是海报系统的最初时期,由不足五人用 Java 写的核心架构。引擎部分,之所以还在用 JSP 和 Freemarker 引擎,是为了兼顾老的系统。
如下图,是海豹系统(CMDB)的界面:
所有的端游、手游的信息会集中到海报系统,意味着资产管理专员可以通过这个平台做所有资源初始化和分配调度。
PAAS平台
通过业务逻辑把各个资源统筹起来,资源所见即所得,更容易的实现了持续集成,通过各项基础服务的组合,实现代码自动化发布、应用管理、环境初始化部署、线上运维一体化集成,提升项目代码编译、测试、发布效率。
PAAS 平台主要职责如下:
提供一致性环境保障。
提供应用多租户隔离以及资源的多租户隔离。
提供服务发现、可弹性伸缩、状态管理、资源分配、动态调度等能力。
支持预发布、一键发布、一键回滚以及自动化部署。
提供透明化的监控、容灾能力。
提供运维、开发、测试多角度业务场景。
如下图,是 PAAS 平台的主要技术选型:
从上图可以看出,PAAS 平台里也包含外部组件,Docker 也包含其中。因为游戏公司大量代码基本都放到 SVN,所以我们也会选在 SVN 来管理。
Docker 容器技术
PAAS 平台的设计中,核心部分是 Docker。那搜狐畅游的 Docker 是如何设计的呢?
如下,是原 Docker 架构图:
如下,是最终版的 Docker 架构图:
从 2014 年至今,我们已经迭代过两个版本,搜狐畅游在容器监控数据共享、稳定性和镜像管理等方面进行了优化。
如下图,是技术演化对比:
因 Ceph 副本之间不稳定,不支持集群共享,所以改成 NFS+DRBD。因 Consul 集群 Leader 切换频繁,业务数据不同步,负载过高,改成 Etcd,来保证数据同步统一。
为应对 cAdvisor 无法汇总,无法查看历史数据的问题,我们自研了 Hunter。操作系统从 2.6 升级到 3.18,应对运行久了后 devicemapper 的信息无法写入导致系统异常的问题。
混合云结构
畅游运维体系最底层采用的是混合云结构,开始考虑的方式是直接接入所有公有云,用专业的方式打通,但游戏需要 BGP(网关协议)。
这意味着必须多线接入,除电信、联通外,所有的小区宽带,第三方宽带也必须要接入,所以需要选择混合云的结构。
选择混合云相比畅游 IDC 降低成本在 20% 左右,并且使资源弹性,云上云下,扩缩容更快速。在可靠性方面,不仅可实现异地双活,还有抗攻击、DNS 劫持、冗余可靠等优势。
畅游运维管理体系的下一步探索
畅游运维管理体系的下一步将把持续交付的分层能力和公共服务标准化作为探索方向。
持续交付的分层能力
在畅游运维做自动化时,会利用可持续交付的理念和原则去做。工具开发过程中,一定要注意的问题是:工具越多,工具与工具之间的调用就会出现大量的问题。
所以一定要进行平台化和做成集群式服务,否则成本不会降低,反而故障依旧会很多。
公共服务标准化
如下图,是公共服务平台整合架构:
畅游把 redis、Nginx、MySQL 等集群全部接入,不需要做其他的事情。
写在最后
畅游运维做整个自动化过程中的心得有三个:
简单有效,不要做特别花哨,因为对应用最实际才是有用的,对应用或开发人员来说,最有效及效率最高是最好的。
符合实际业务,不是脱离研发和应用。
高效,游戏特性决定必须高效,快上快下,快速决策。
以上内容根据黎志刚老师在 DevOps 与持续交付专场的演讲内容整理。
摘自:http://www.sohu.com/a/159781943_655957

19-09-07 12:24

9615

0
回复
暂无评论
